Stochastic Spintronic Dataflow Computing
Students: Tianmu Li, Wojciech Romaszkan
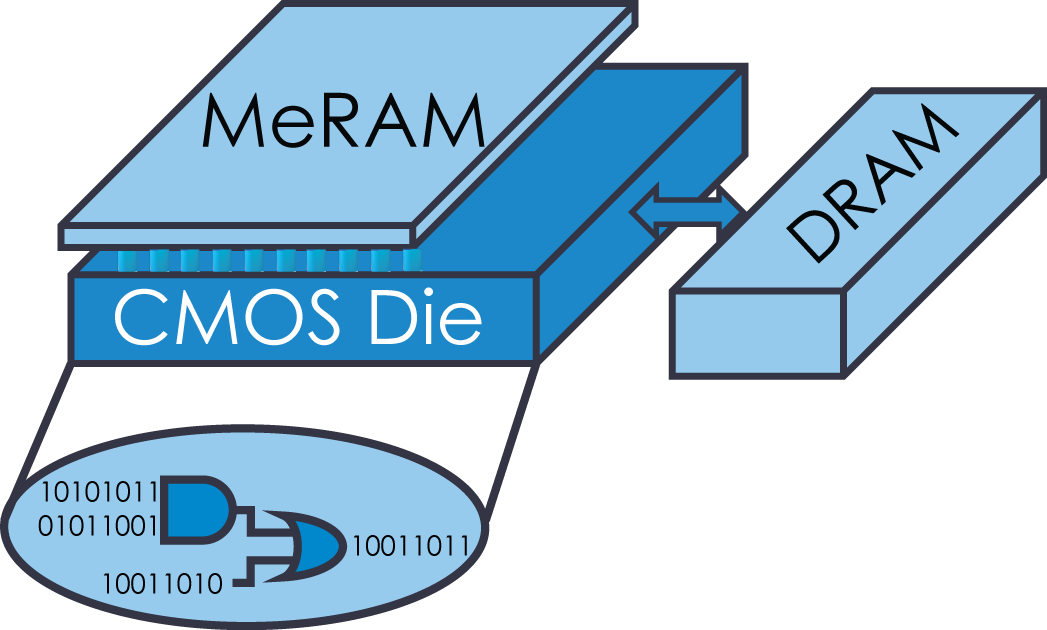
The SSDC project is a collaborative effort between three faculty of the UCLA Electrical and Computer Engineering department – Prof. Kang L. Wang (Device Research Laboratory), Prof. Puneet Gupta (NanoCAD Laboratory), and Prof. Sudhakar Pamarti (Signal Processing & Circuit Engineering Laboratory) – who are experts in nanotechnology, computing systems, design automation, and integrated circuit design. Led by Prof. Sudhakar Pamarti, it brings together spin-based voltage-controlled magnetic memory technology (MeRAM) and an unconventional stochastic computing (SC) paradigm to resolve the dreaded “memory bottleneck” problem. The memory bottleneck represents the limited bandwidth and high energy cost of moving data between the processing and memory units and is arguably the most important challenge confronting modern computing systems, especially in big data applications.
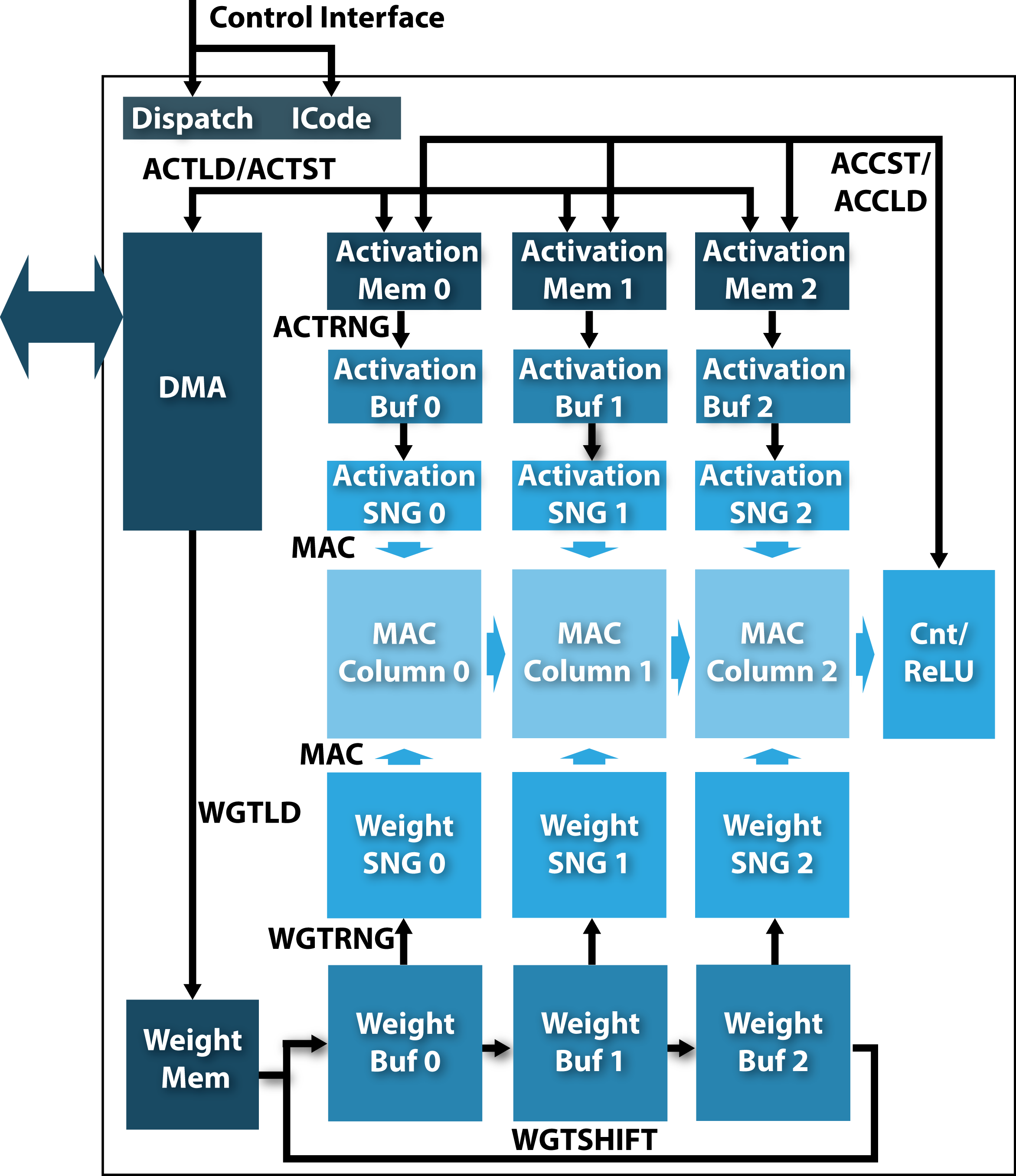
The SC employs a stochastic alternative to traditional number representation (using long random binary bit streams instead of fixed- or floating-point) to enable ultra compact processing hardware. The MeRAM, developed by Prof. Kang Wang’s group exploits the voltage controlled magnetic anisotropy property to achieve the best reported combination of energy, speed, and density among existing and emerging non-volatile memory technologies.
The combination of ultra-compact SC hardware and the dense, non-volatile MeRAM integrated on the same Silicon die offers great energy and latency improvements. The SSDC project aims to demonstrate up to 60x energy reduction for example data intensive machine learning tasks.
This project is funded by the FRANC (Foundations Required for Novel Compute) program within DARPA’s Electronics Resurgence Initiative (ERI) aimed at solving fundamental challenges confronting the growth of microelectronics long after Moore’s law is over.
Collaborators: Professor Sudhakar Pamarti (UCLA), Professor Kang L. Wang (UCLA)
SWIS – Shared Weight bIt-Sparsity Quantization
Students: Shurui Li, Wojciech Romaszkan, Alexander Graening
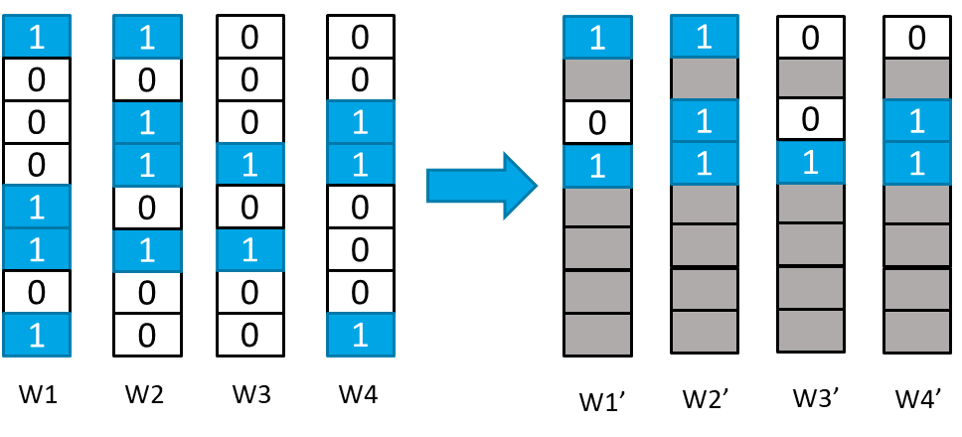
Quantization is spearheading the increase in performance and efficiency of neural network computing systems, making headway into commodity hardware. SWIS (Shared Weight bItSparsity), is a quantization framework for efficient neural network inference acceleration delivering improved performance and storage compression through an offline weight decomposition and scheduling algorithm. SWIS can achieve up to 54.3% (19.8%) point accuracy improvement compared to weight truncation when quantizing MobileNet-v2 to 4 (2) bits post-training (with retraining) showing the strength of leveraging shared bit-sparsity in weights. SWIS accelerator gives up to 6×speedup and 1.9×energy improvement overstate of the art bit-serial architectures.
3PXNet: Pruned-Permuted-Packed XNOR Networks 
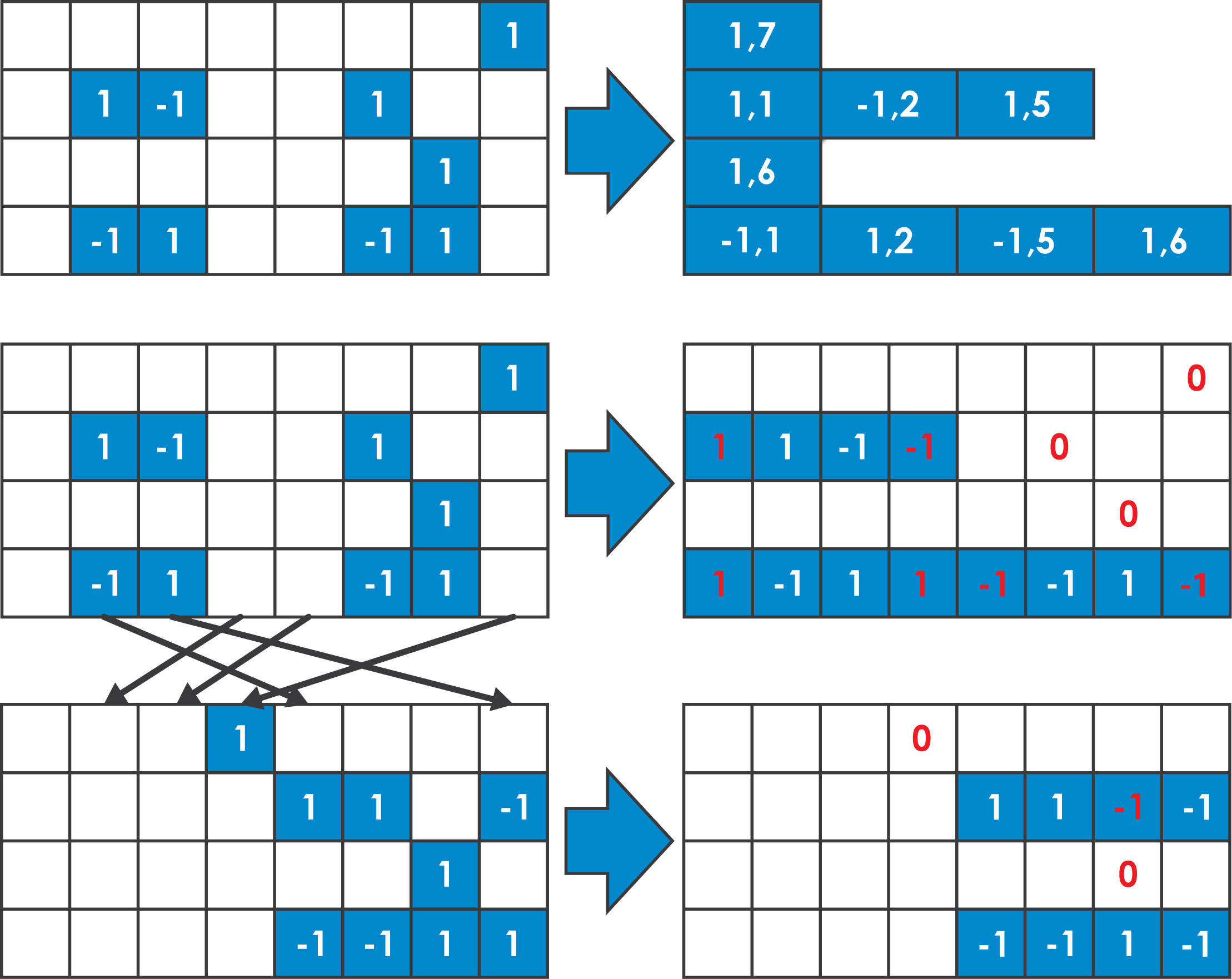
Students: Tianmu Li, Wojciech Romaszkan
As the adoption of Neural Networks continues to proliferate different classes of applications and systems, edge devices have been left behind. Their strict energy and storage limitations make them unable to cope with the enormous sizes of commonly used models. While many compression methods, such as precision reduction and sparsity, have been proposed to alleviate this, they do not go quite far enough. To push size reduction to its absolute limits, we combine binarization with sparsity in Pruned-Permuted-Packed XNOR Networks (3PXNet), which can be efficiently implemented on even the smallest of embedded microcontrollers. 3PXNets can reduce model sizes by up to 38X and reduce runtime by up to 3X, compared with already compact conventional binarized implementations with less than 3% accuracy reduction. 3PXNet is released as an open-source library targeting edge devices. The library is complete with training methodology and model generating scripts, making it easy and fast to deploy.
3PXNet is available at: https://github.com/nanocad-lab/3pxnet
Publications
- [1]
![[PDF]](https://nanocad.ee.ucla.edu/wp-content/plugins/papercite/img/pdf.png) J. Yang, T. Li, W. Romaszkan, P. Gupta, and S. Pamarti, “A 65nm 8-bit All-Digital Stochastic-Compute-In-Memory Deep Learning Processor,” in IEEE Asian Solid-State Circuits Conference, 2022, p. 2
J. Yang, T. Li, W. Romaszkan, P. Gupta, and S. Pamarti, “A 65nm 8-bit All-Digital Stochastic-Compute-In-Memory Deep Learning Processor,” in IEEE Asian Solid-State Circuits Conference, 2022, p. 2 [Bibtex]
@inproceedings{C121,
author = {Yang, Jiyue and Li, Tianmu and Romaszkan, Wojciech and Gupta, Puneet and Pamarti, Sudhakar},
booktitle = {{IEEE Asian Solid-State Circuits Conference}},
doi = {},
keywords = {mledge},
month = {November},
note = {},
pages = {2},
title = {{A 65nm 8-bit All-Digital Stochastic-Compute-In-Memory Deep Learning Processor}},
year = {2022}
}[Bibtex]
@inproceedings{C120,
author = {Romaszkan, Wojciech and Li, Tianmu and Gupta, Puneet},
booktitle = {{ACM/IEEE International Conference on Compilers, Architecture, and Synthesis for Embedded Systems (CASES), published in ESWEEK special issue of the IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)}},
doi = {},
keywords = {mledge},
month = {October},
note = {Best paper nomination},
pages = {12},
title = {{SASCHA - Sparsity-Aware Stochastic Computing Hardware Architecture for Neural Network Acceleration}},
year = {2022}
}[Bibtex]
@article{J72,
author = {Romaszkan, Wojciech and Li, Tianmu and Gupta, Puneet},
booktitle = {{ACM/IEEE International Conference on Compilers, Architecture, and Synthesis for Embedded Systems (CASES), published in ESWEEK special issue of the IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)}},
doi = {},
keywords = {mledge},
month = {October},
note = {Best paper nomination},
pages = {12},
title = {{SASCHA - Sparsity-Aware Stochastic Computing Hardware Architecture for Neural Network Acceleration}},
year = {2022}
}[Bibtex]
@inproceedings{C119,
author = {Li, Shurui and Gupta, Puneet},
booktitle = {{Conference on Machine Learning and Systems (MLSys)}},
doi = {},
keywords = {mledge},
month = {August},
note = {},
pages = {10},
title = {{Bit-serial Weight Pools: Compression and Arbitary Precision Execution of Neural Networks on Resource Constrained Processors}},
year = {2022}
}[Bibtex]
@article{J70,
author = {Romaszkan, Wojciech and Li, Tianmu and Garg, Rahul and Yang, Jiyue and Pamarti, Sudhakar and Gupta, Puneet},
journal = {{IEEE Solid State Circuits Letters}},
keywords = {mledge},
month = {August},
publisher = {{IEEE}},
title = {{ A 4.4-75 TOPS/W 14nm Programmable, Performance- and Precision-Tunable All-Digital Stochastic Computing Neural Network Inference Accelerator}},
year = {2022}
}[Bibtex]
@inproceedings{C113,
author = {Li, Shurui and Romaszkan, Wojciech and Graening, Alexander and Gupta, Puneet},
booktitle = {{International Research Symposium on Tiny Machine Learning (tinyML)}},
doi = {},
keywords = {mledge, quantization, systolic array},
month = {March},
note = {},
pages = {},
title = {{SWIS - Shared Weight bIt Sparsity for Efficient Neural Network Acceleration}},
year = {2021}
}[Bibtex]
@inproceedings{C112,
author = {Li, Tianmu and Romaszkan, Wojciech and Pamarti, Sudhakar and Gupta, Puneet},
booktitle = {{IEEE/ACM Design, Automation and Test in Europe}},
doi = {},
keywords = {mledge},
month = {February},
note = {},
pages = {},
title = {{GEO: Generation and Execution Optimized Stochastic Computing Accelerator for Neural Networks}},
year = {2021}
}[Bibtex]
@inproceedings{C109,
author = {Romaszkan, Wojciech and Li, Tianmu and Melton, Tristan and Pamarti, Sudhakar and Gupta, Puneet},
booktitle = {{IEEE/ACM Design, Automation and Test in Europe}},
doi = {10.23919/DATE48585.2020.9116289},
keywords = {mledge},
month = {March},
note = {Best paper nomination},
pages = {768-773},
title = {{ACOUSTIC: Accelerating Convolutional Neural Networks through Or-Unipolar Skipped Stochastic Computing}},
year = {2020}
}[Bibtex]
@article{J63,
author = {Romaszkan, Wojciech and Li, Tianmu and Gupta, Puneet},
journal = {{ACM Transactions on Embedded Computing Systems (TECS)}},
keywords = {mledge, 3pxnet},
month = {November},
publisher = {ACM},
title = {{3PXNet: Pruned-Permuted-Packed XNOR Networks for Edge Machine Learning}},
year = {2019}
}[Bibtex]
@inproceedings{C95,
author = {Wang, Shaodi and Pal, Saptadeep and Li, Tianmu and Pan, Andrew and Grezes, Cecile and Amiri, P. Khalili and Wang, Kang L. and Chui, Chi On and Gupta, Puneet},
booktitle = {{IEEE/ACM Design, Automation and Test in Europe}},
keywords = {mledge,Negative differential resistance, Magnetic tunnel junction, stochastic computing, stochastic bitstream generator, non-volatile computing},
month = {March},
note = {Best paper nomination},
paperurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/C95_paper.pdf},
slideurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/C95_slides.pdf},
title = {{H}ybrid {VC-MTJ/CMOS} {N}on-volatile {S}tochastic {L}ogic for {E}fficient {C}omputing},
year = {2017}
}