Students: Saptadeep Pal
With the emergence of new applications, new business models, and new data processing techniques (e.g., deep learning), the need for parallel hardware
has never been stronger. Unfortunately, there is an equally strong countervailing trend. Parallel hardware necessitates low overhead communication between different computing nodes. However, the overhead of communication has been increasing at an alarming pace and is expected to be worse in future as communication energy, latency, and bandwidth scale much worse than computation. As a result, increasing communication overhead is already threatening computer system scaling.
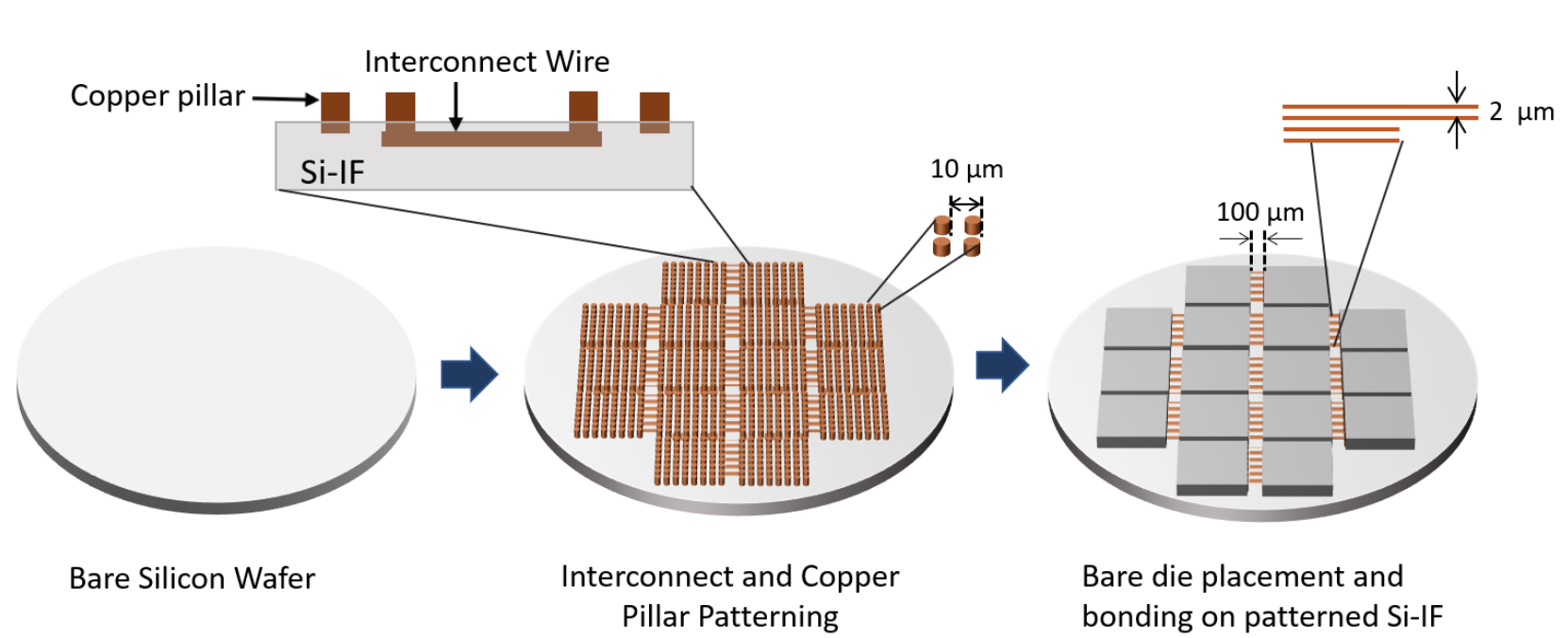
One approach to dramatically reduce communication overheads is waferscale (WS) processing, where a processor chip is of the size of an entire 300mm wafer. However, WS processors have been historically deemed impractical due to yield issues of building a large monolithic WS chip. Most yield loss in chipmaking comes from defects in the transistor layers or in the high-density lower metal layers.
We take a different route towards realizing WS processors using the Silicon-Interconnection Fabric (Si-IF) technology. Here smaller pre-manufactured dies are directly bonded onto a silicon wafer, enables one to build a WS system without the corresponding yield issues. The WS substrate only contains relatively low-density metal layers on the wafer, roughly the same density as the upper layers of a system on a chip, and is only used for high-density inter-die interconnections.
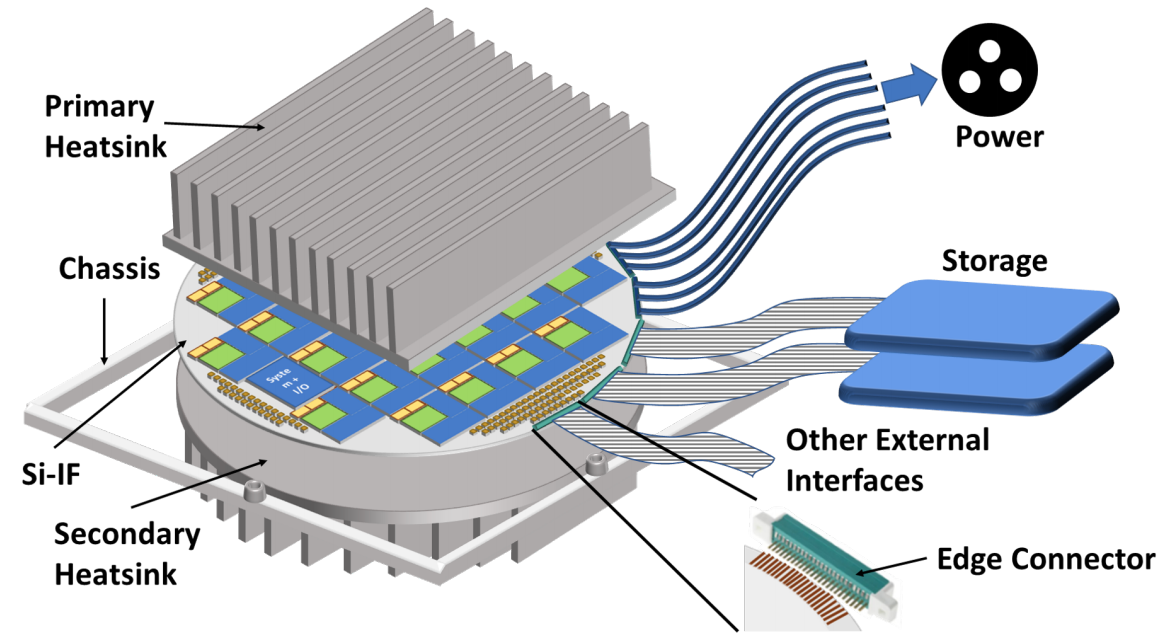
Related to Si-IF based WS-Processors, we specifically study and explore computer architecture solutions for massively parallel WS processors. We also develop system design solutions for dielet assembly on high performance interconnect substrates such as Si-IF, interposers etc. Our recent proposal of a waferscale-GPU can achieve up to 18.9x speedup and 143x EDP benefit compared against equivalent MCM-GPU based implementation on PCB. We are currently working on a massively parallel general purpose waferscale processor prototype built using ARM processors.
Collaborators: CHIPS-UCLA, Rakesh Kumar (UIUC)
Publications
- [1]
![[PDF]](https://nanocad.ee.ucla.edu/wp-content/plugins/papercite/img/pdf.png) M. Niemier, Z. Enciso, M. M. Sharifi, X. S. Hu, I. O’Conner, A. Graening, R. Sharma, P. Gupta, J. Castrillon, J. P. C. Lima, N. Afroze, A. Khan, and J. Ryckaert, “Smoothing Disruption Across the Stack: Tales of Memory, Heterogeneity, & Compilers,” in IEEE/ACM Design, Automation and Test in Europe, 2024, p. 10
M. Niemier, Z. Enciso, M. M. Sharifi, X. S. Hu, I. O’Conner, A. Graening, R. Sharma, P. Gupta, J. Castrillon, J. P. C. Lima, N. Afroze, A. Khan, and J. Ryckaert, “Smoothing Disruption Across the Stack: Tales of Memory, Heterogeneity, & Compilers,” in IEEE/ACM Design, Automation and Test in Europe, 2024, p. 10 [Bibtex]
@inproceedings{IP19,
author = {Niemier, Michael and Enciso, Zephan and Sharifi, Mohammed Mehdi and Hu, Xiaobo Sharon and O'Conner, Ian and Graening, Alexander and Sharma, Ravit and Gupta, Puneet and Castrillon, Jeronimo and Lima, J.P.C. and Afroze, Nashrah and Khan, Asif and Ryckaert, Julien},
booktitle = {{IEEE/ACM Design, Automation and Test in Europe}},
doi = {},
keywords = {chiplets,wsi},
month = {March},
note = {},
pages = {10},
title = {{Smoothing Disruption Across the Stack: Tales of Memory, Heterogeneity, & Compilers}},
year = {2024}
}[Bibtex]
@inproceedings{C124,
author = {Graening, Alexander and Pal, Saptadeep and Gupta, Puneet},
booktitle = {{Proc. ACM/IEEE Design Automation Conference (DAC)}},
doi = {},
keywords = {chiplets,wsi},
month = {July},
note = {},
pages = {6},
title = {{Chiplets: How Small is too Small?}},
year = {2023}
}[Bibtex]
@inproceedings{C116,
author = {Pal, Saptadeep and Liu, Jingyang and Alam, Irina and Cebry, Nicholas and Suhail, Haris and Bu, Shi and Iyer, Subramanian S. and Pamarti, Sudhakar and Kumar, Rakesh and Gupta, Puneet},
booktitle = {{Proc. ACM/IEEE Design Automation Conference (DAC)}},
doi = {},
keywords = {wsi},
month = {December},
note = {},
pages = {},
title = {{Designing a 2048-Chiplet, 14336-Core Waferscale Processor}},
year = {2021}
}[Bibtex]
@inproceedings{C114,
author = {Pal, Saptadeep and Sahoo, Krutikesh and Alam, Irina and Suhail, Haris and Kumar, Rakesh and Pamarti, Sudhakar and Gupta, Puneet and Iyer, Subramanian S.},
booktitle = {{IEEE Electronic Components and Technology Conference (ECTC)}},
doi = {},
keywords = {wsi},
month = {June},
note = {},
pages = {},
title = {{I/O Architecture, Substrate Design, and Bonding Process for a Heterogeneous Dielet-Assembly based Waferscale Processor}},
year = {2021}
}[Bibtex]
@inproceedings{C111,
address = {New York, NY, USA},
author = {Pal, Saptadeep and Gupta, Puneet},
booktitle = {{System-Level Interconnect - Problems and Pathfinding Workshop}},
keywords = {wsi},
location = {San Diego, California},
month = {November},
numpages = {8},
publisher = {ACM},
series = {SLIP '20},
title = {{Pathfinding for 2.5D Interconnect Technologies}},
year = {2020}
}[Bibtex]
@article{J66,
author = {Pal, Saptadeep and Petrisko, Daniel and Kumar, Rakesh and Gupta, Puneet},
doi = {https://ieeexplore.ieee.org/document/8998304},
journal = {{IEEE Transactions on Very Large Scale Integration Systems}},
keywords = {{2.5-D integration, chiplet assembly, micro-architectural design space exploration (DSE), multichiplet optimization, wsi}},
publisher = {{IEEE}},
title = {{Design Space Exploration for Chiplet Assembly Based Processors}},
year = {2020}
}[Bibtex]
@inproceedings{C107,
author = {Pal, Saptadeep and Petrisko, Daniel and Tomei, Matthew and Iyer, Subramanian S. and Gupta, Puneet and Kumar, Rakesh},
booktitle = {{IEEE International Symposium on High-Performance Computer Architecture (HPCA)}},
doi = {10.1109/HPCA.2019.00042},
issn = {1530-0897},
keywords = {wsi},
month = {February},
pages = {250-263},
paperurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/C106_paper.pdf},
title = {{Architecting Waferscale Processors - A GPU Case Study}},
year = {2019}
}[Bibtex]
@inproceedings{C100,
author = {Pal, Saptadeep and Petrisko, Daniel and Bajwa, Adeel and Iyer, Subramanian S. and Kumar, Rakesh and Gupta, Puneet},
booktitle = {{IEEE International Symposium on High-Performance Computer Architecture (HPCA)}},
keywords = {wsi},
month = {February},
paperurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/C100_paper.pdf},
title = {{A Case for Packageless Processors}},
year = {2018}
}[Bibtex]
@inproceedings{C96,
author = {Jangam, SivaChandra and Pal, Saptadeep and Bajwa, Adeel and Pamarti, Sudhakar and Gupta, Puneet and Iyer, Subramanian S.},
booktitle = {{IEEE Electronic Components and Technology Conference (ECTC)}},
keywords = {Silicon Interconnect Fabric; Thermal Compression Bonding; Fine Pitch Interconnect, SuperCHIPS, wsi},
month = {May},
paperurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/C96_paper.pdf},
slideurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/C96_slides.pdf},
title = {{L}atency, {B}andwidth and {P}ower {B}enefits of the {S}uper{CHIPS} {I}ntegration {S}cheme},
year = {2017}
}[Bibtex]
@inproceedings{IP17,
author = {Pal, Saptadeep and Iyer, Subramanian S. and Gupta, Puneet},
booktitle = {{IEEE International Conference on Rebooting Computing}},
keywords = {wsi},
paperurl = {https://nanocad.ee.ucla.edu/pub/Main/Publications/IP17_paper.pdf},
title = {Advanced Packaging and Heterogeneous Integration to Reboot Computing},
year = {2017}
}